



 การเขียนโปรแกรมภาษาไพธอนประมวลผลภาพด้วย OpenCV
การเขียนโปรแกรมภาษาไพธอนประมวลผลภาพด้วย OpenCV
เขียนโดย ดร.จักรกฤษณ์ แสงแก้ว วันที่ 4 มีนาคม 2563
OpenCV
» OpenCV เป็นไลบรารี่สำหรับงานประมวลผลภาพพัฒนาโดยบริษัทอินเทล ใช้งานได้โดยไม่มีค่าใช้จ่ายเกี่ยวกับลิขสิทธิ์ซอต์แวร์ » การเปิดภาพด้วย OpenCV จะอยู่ในโหมดสีแบบ BGR เสมอ (Blue Green Red) » เมื่อต้องการให้แสดง RGB ต้องเปลี่ยนจาก BGR2RGB ก่อน
import cv2
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread('/Users/ayang/Pictures/ForTest/test.jpg')
img = cv2.cvtColor(img, cv2.cv.CV_BGR2RGB)
plt.imshow(img)
plt.show()
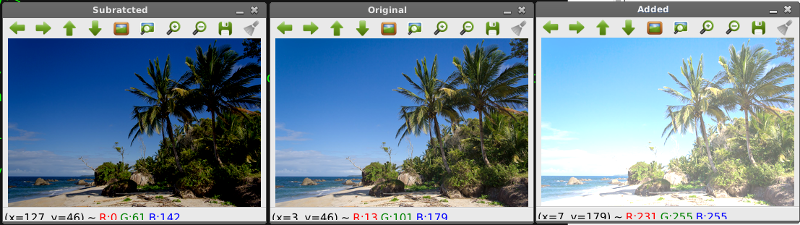
ฟังก์ชั่น add และ subtract
» ฟังก์ชั่น cv2.add() จะมีค่าผลรวมไม่เกิน 255 และผลลัพธ์ไม่มีค่าน้อยกว่า 0 หมายถึง ผลลัพธ์ของฟังก์ชั่น cv.add() จะมีค่าในช่วง 0 ถึง 255 เท่านั้น เช่น print "max of 255: %s" % str(cv2.add(np.uint8([200]), np.uint8([100]))) หมายถึง ให้บวกเลข 200 + 100 ซึ่งควรจะได้ 300 แต่ cv2.add(200,100) จะให้ผลลัพธ์เป็นค่าสูงสุด คือ 255 เท่านั้น
» ฟังก์ชั่น cv2.subtract() มีค่าผลลัพธ์ในช่วง 0 ถึง 255 เช่นเดียวกับ ฟังก์ชั่น cv2.add() เช่น print "min of 0: %s" % str(cv2.subtract(np.uint8([50]), np.uint8([100]))) หมายถึง 50-100 ซึ่งมีค่าเท่ากับ -50 แต่ OpenCV ให้ผลลัพธ์เป็นค่าต่ำสุดคือ 0 ไม่ใช่ -50
» คำสั่ง matrix = np.ones(image.shape, dtype="uint8") * 100 คือ การสร้างเมตริกซ์ด้วยขนาด 100 จากนั้น เรียกคำสั่ง added = cv2.add(image, matrix) หมายถึง การบวกค่า 100 เข้าไปในทุก ๆ ค่าสีของภาพ
import argparse
import numpy as np
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True, help="Path to the image")
args = vars(ap.parse_args())
image = cv2.imread(args["image"])
cv2.imshow("Original", image)
# OpenCV utilizes clipping, and will never exceed 255 or go below 0
print "max of 255: %s" % str(cv2.add(np.uint8([200]), np.uint8([100])))
print "min of 0: %s" % str(cv2.subtract(np.uint8([50]), np.uint8([100])))
# Numpy utilizes wrap around when reaching the maximum or minimum value
print "Wrap around %s" % str(np.uint8([200]) + np.uint8([100]))
print "Wrap around %s" % str(np.uint8([50]) - np.uint8([100]))
matrix = np.ones(image.shape, dtype="uint8") * 100 # Create a matrix with the dimensions of image, and 100 in each slot
added = cv2.add(image, matrix) # Add 100 to all pixel values
cv2.imshow("Added", added)
matrix = np.ones(image.shape, dtype="uint8") * 50 # Create a matrix with the dimensions of image, and 50 in each slot
subtracted = cv2.subtract(image, matrix) # Subtract 50 from all pixel values
cv2.imshow("Subratcted", subtracted)
ผลลัพธ์
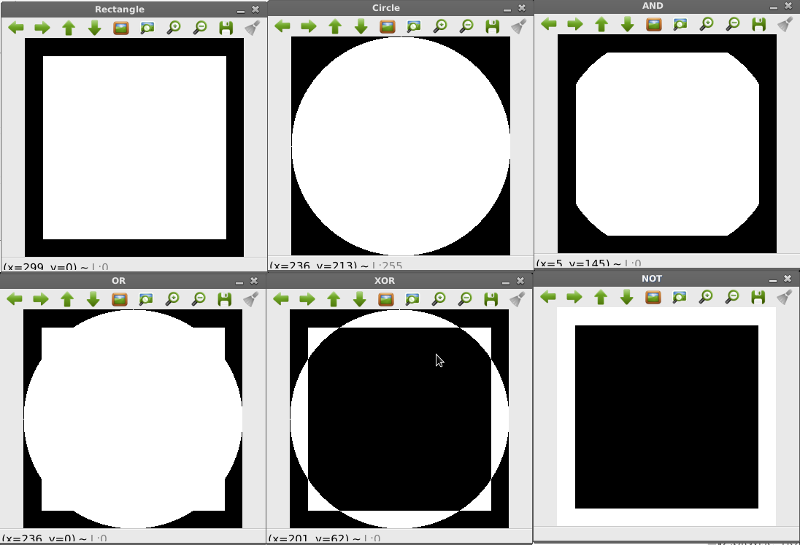
การดำเนินการระดับบิต (Bitwise)
OpenCV อนุญาตให้ดำเนินการกับภาพในระดับบิต ซึ่งประกอบด้วย 1) การ AND 2) การ OR 3) การ XOR (Exclusive OR) และ 4) การ Not บรรทัดที่ 5 สร้างสี่เหลี่ยมผืนผ้า บรรทัด 9 สร้างวงกลม บรรทัด 12 ทำโอเปอร์เรเตอร์ AND ระหว่างภาพสี่เหลี่ยมและวงกลม ด้วยคำสั่ง bitwise_and บรรทัด 15 ทำโอเปอร์เรเตอร์ OR ระหว่างภาพสี่เหลี่ยมและวงกลม ด้วยคำสั่ง bitwise_or บรรทัด 18 ทำโอเปอร์เรเตอร์ XOR ระหว่างภาพสี่เหลี่ยมและวงกลม ด้วยคำสั่ง bitwise_xor บรรทัด 22 ทำโอเปอร์เรเตอร์ NOT ระหว่างภาพสี่เหลี่ยมและวงกลม ด้วยคำสั่ง bitwise_not
import numpy as np
import cv2
rectangle = np.zeros((300, 300), dtype="uint8")
cv2.rectangle(rectangle, (25, 25), (275, 275), 255, -1)
cv2.imshow("Rectangle", rectangle)
circle = np.zeros((300, 300), dtype="uint8")
cv2.circle(circle, (150, 150), 150, 255, -1)
cv2.imshow("Circle", circle)
bitwise_and = cv2.bitwise_and(rectangle, circle) # Checks if pixels in the same position greater than 0 in both images
cv2.imshow("AND", bitwise_and)
bitwise_or = cv2.bitwise_or(rectangle, circle) # Checks if pixels in the same position greater than 0 in either image
cv2.imshow("OR", bitwise_or)
bitwise_xor = cv2.bitwise_xor(rectangle,
circle) # Pixels in the same position greater than 0 in either image but not both
cv2.imshow("XOR", bitwise_xor)
bitwise_not = cv2.bitwise_not(rectangle) # A bitwise NOT inverts the on and off pixels in an image.
cv2.imshow("NOT", bitwise_not)
ผลลัพธ์
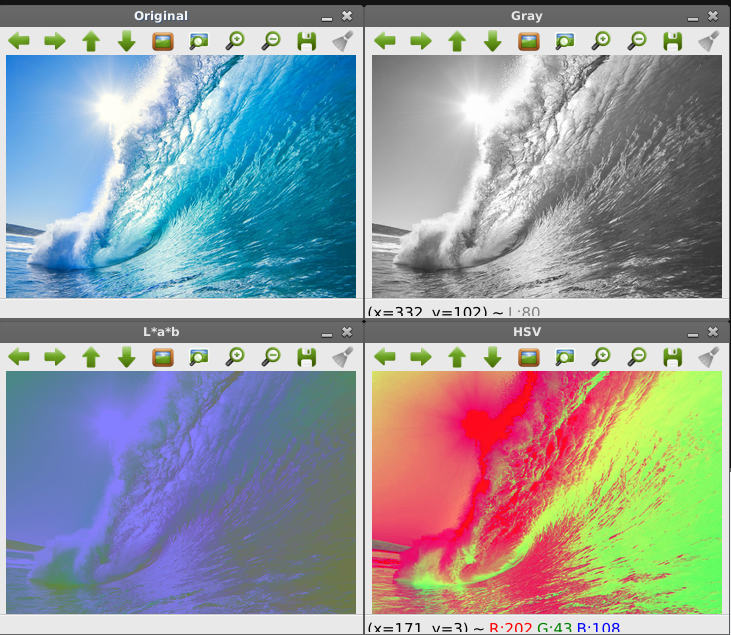
การแปลงโมเดลสี (Color Model)
ระบบสีมี 4 แบบ ได้แก่ 1) RGB 2) CMYK 3)HSB และ 4) L*a*b
» ระบบสี RGB มีแม่สี 3 สี ได้แก่ สีแดง (Red) , สีเขียว (Green) และสีน้ำเงิน (Blue) โดยใช้แม่สีทั้งสามสีนี้เพื่อสร้างสีต่าง ๆ จากการผสมสีหลักทั้งสามในสัดส่วนที่แตกต่างกันออกไป
» CMYK คือ แม่สีงานพิมพ์ มี 4 สี เป็นองค์ประกอบ ได้แก่ 1. สีน้ำเงินเขียว (Cyan) 2. สีม่วงแดง (Magenta) 3. สีเหลืองส้ม (Yellow) และ 4. สีดำ (Black)
» HSB คือ เป็นระบบสีที่มี 3 สีเป็นองค์ประกอบ ได้แก่ 1) สีสัน (Hue) 2) ความอิ่มตัวของสี (Saturation) 3) ความสว่างของสี (Brightness)
» L*a*b เป็น ระบบสีจากทฤษฎีสีคู่ตรงข้าม นิยมใช้กับงานสิ่งพิมพ์สะท้อนแสง ประกอบด้วย 3 สี คือ 1) L* คือความสว่างของสีนั้น (ขาว-ดำ) 2) a* คือระดับความเป็นสีเขียวหรือสีแดง 3) b* ค่าระดับสีเหลืองหรือสีน้ำเงิน
import argparse
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True, help="Path to the image")
args = vars(ap.parse_args())
image = cv2.imread(args["image"])
cv2.imshow("Original", image)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # Convert RGB to Gray scale
cv2.imshow("Gray", gray)
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV) # Convert RGB to HSV
cv2.imshow("HSV", hsv)
lab = cv2.cvtColor(image, cv2.COLOR_BGR2LAB) # Convert RGB to LAB
cv2.imshow("L*a*b", lab)
ผลลัพธ์
การตัดบางส่วนของภาพ (Clopping)
การตัดบางส่วนของภาพ ใช้การระบุตำแหน่งด้านบนซ้ายของภาพและระบุพิกัดด้านล่างขวาของภาพ โค๊ด cropped = image[30:120, 240:335] หมายถึง ตัดเอาตำแหน่งพิกัดบนซ้าย คือ 30,120 และพิกัดล่างขวา คือ 240,335 พิกเซลออกมาจากภาพต้นฉบับ
# Cropping in OpenCV simply utilizes array slicing in Numpy.
import argparse
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True, help="Path to the image")
args = vars(ap.parse_args())
image = cv2.imread(args["image"])
cv2.imshow("Original", image)
# cropping an image manually
cropped = image[30:120, 240:335] # If used on the image trex.png this encapsulates its head
cv2.imshow("Cropped image", cropped)
ผลลัพธ์
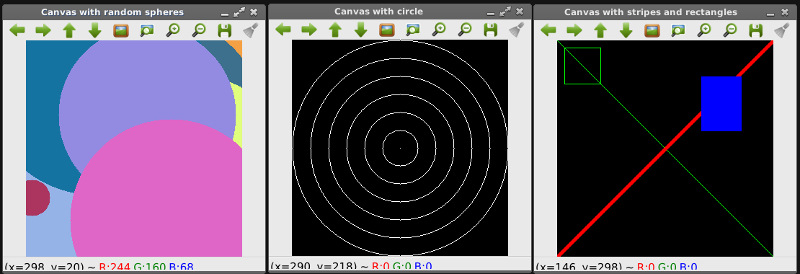
การวาดภาพจากองค์ประกอบพื้นฐาน ได้แก่ เส้นตรง สี่เหลี่ยม วงกลม เป็นต้น
คำสั่งสำหรับวาดองค์ประกอบพื้นฐานของภาพ ได้แก่ เส้นตรง สี่เหลี่ยม วงกลม เป็นต้น การวาดเส้นตรง ใช้คำสั่ง cv2.line() เช่น cv2.line(canvas, (0, 0), (300, 300), green) วาดวงกลม จากพิกัด 0,0 ไปยัง 300,300 ด้วยสีเขียว เมื่อสีเขียว กำหนด = [0,255,0] คือ องค์ประกอบของสีเขียวมีค่าสูงสุด คือ 255 (8 บิต)] วาดสี่เหลี่ยมใช้คำสั่ง cv2.rectangle() วาดวงกลมใช้คำสั่ง cv2.circle()
import numpy as np
import cv2
canvas = np.zeros((300, 300, 3), dtype="uint8") # Create a canvas with the dimension 300x300
# CV2 stores all the colour of the pixels in reverse order (Blue, Green, Red)
green = (0, 255, 0)
red = (0, 0, 255)
blue = (255, 0, 0)
white = (255, 255, 255)
cv2.line(canvas, (0, 0), (300, 300), green)
cv2.line(canvas, (300, 0), (0, 300), red, 3)
cv2.rectangle(canvas, (10, 10), (60, 60), green)
cv2.rectangle(canvas, (200, 50), (255, 125), blue, -1)
cv2.imshow("Canvas with stripes and rectangles", canvas)
canvas = np.zeros((300, 300, 3), dtype="uint8") # Create a canvas with the dimensions 300x300s
(centerX, centerY) = (canvas.shape[1] / 2, canvas.shape[0] / 2) # The middle of the canvas
for r in xrange(0, 175, 25): # From 0-150 with a step value of 25
cv2.circle(canvas, (centerX, centerY), r, white)
cv2.imshow("Canvas with circle", canvas)
canvas = np.zeros((300, 300, 3), dtype="uint8") # Create a canvas with the dimensions 300x300s
for i in xrange(0, 25):
radius = np.random.randint(5, high=200)
colour = np.random.randint(0, high=256,
size=(3,)).tolist() # Create three different values from 0-256 and save them as a list
center = np.random.randint(0, high=300,
size=(2,)).tolist() # Create two different values from 0-300 and save them as a list
cv2.circle(canvas, tuple(center), radius, colour, -1)
cv2.imshow("Canvas with random spheres", canvas)
ผลลัพธ์
การกลับภาพ (Flipping)
การกลับภาพใช้คำสั่ง cv2.flip() โดยมีการกลับในแนวนอน (1) , การกลับภาพแนวตั้ง (0) และการกลับทั้งแนวนอนและแนวตั้ง (-1)
import cv2
image = cv2.imread(args["raspberrypi.jpg"])
cv2.imshow("Original", image)
flipped = cv2.flip(image, 1)
cv2.imshow("Flipped Horizontally", flipped)
flipped = cv2.flip(image, 0)
cv2.imshow("Flipped Vertically", flipped)
flipped = cv2.flip(image, -1)
cv2.imshow("Flipped Horizontally & Vertically", flipped)
ผลลัพธ์
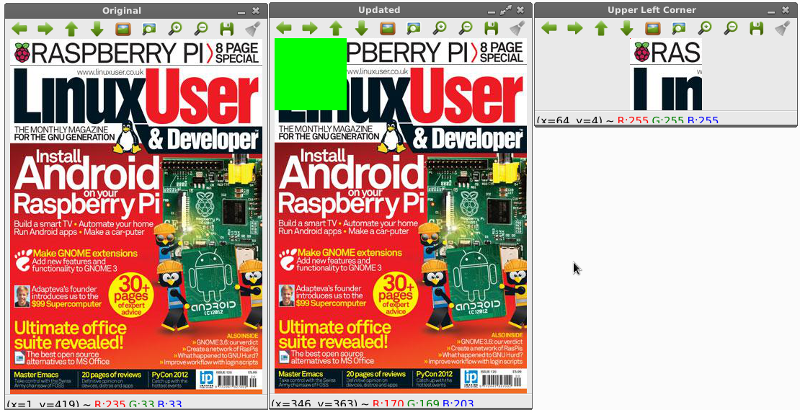
การอ่านบางส่วนของภาพและกำหนดค่าให้พื้นที่ดังกล่าว
ตัวอย่างนี้แสดงให้เห็นความสามารถในการเข้าถึงอาร์เรย์สองมิติเพื่อเลือกบางส่วนของภาพซึ่งทำได้อย่างง่ายดายเพียงกำหนดช่วงของข้อมูลที่ต้องการเท่านั้น
import cv2
image = cv2.imread("raspberry-py-3.jpg")
cv2.imshow("Original", image)
(b, g, r) = image[0, 0] # CV2 stores all the colour of the pixels in reverse order (Blue, Green, Red)
print "Pixel at (0, 0) - Red: %d, Green: %d, Blue %d" % (r, g, b)
image[0, 0] = (0, 0, 255)
(b, g, r) = image[0, 0]
print "Pixel at (0, 0) - Red: %d, Green: %d, Blue %d" % (r, g, b)
corner = image[0:100, 0:100]
cv2.imshow("Upper Left Corner", corner)
image[0:100, 0:100] = (0, 255, 0) # CV2 stores all the colour of the pixels in reverse order (Blue, Green, Red)
cv2.imshow("Updated", image)
ผลลัพธ์
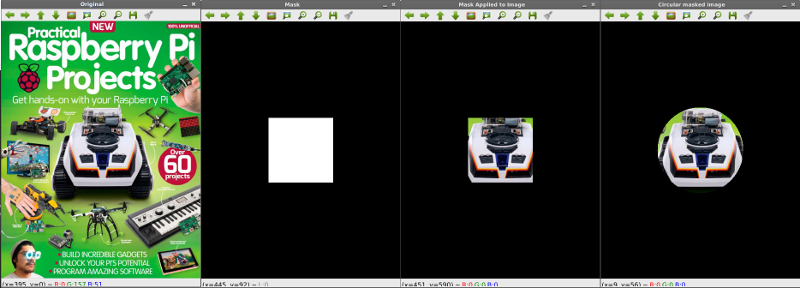
การเลือกขอบเขตข้อมูลภายในภาพด้วย Mask
หลักการเลือกขอบเขตของภาพด้วย Mask เป็นการใช้ตัวกรองที่มีสีขาวและสีดำ มาวางทับภาพต้นฉบับ และบริเวณใดเป็นสีขาวจะทำการดึงข้อมูลจากภาพต้นฉบับออกมา ส่วนหน้ากากที่เป็นพื้นที่สีดำ จะไม่ทำการดึงภาพจากต้นฉบับออกมา ในขั้นตอนแรก เราจะทำการทดลองสร้างหน้ากาก ในตัวอย่างนี้ใช้กล่องสี่เหลี่ยม โดยตัดมาจากตรงกลางภาพ ขนาด 75x75 พิกเซล ในขั้นสอง จะใช้ mask ที่เป็นวงกลม โดยกำหนดรัศมีวงกลม 100 พิกเซล จากกึ่งกลางภาพ ทำการกรองด้วยคำสั่ง cv2.bitwise_and()
import numpy as np
import cv2
image = cv2.imread("raspberry-4.jpg")
cv2.imshow("Original", image)
mask = np.zeros(image.shape[:2], dtype="uint8") # Create a mask that is the size of the original image with only zeros
(center_x, center_y) = (image.shape[1] / 2, image.shape[0] / 2) # Calculate the center of the image
cv2.rectangle(mask,
(center_x - 75, center_y - 75),
(center_x + 75, center_y + 75),
255, -1) # Create a 75x75 square with the same center filled with white pixels
cv2.imshow("Mask", mask)
masked = cv2.bitwise_and(image, image, mask=mask)
cv2.imshow("Mask Applied to Image", masked)
mask = np.zeros(image.shape[:2], dtype="uint8")
cv2.circle(mask, (center_x, center_y), 100, 255, -1)
masked = cv2.bitwise_and(image, image, mask=mask)
cv2.imshow("Circular masked image", masked)
ผลลัพธ์
การปรับขนาดภาพ (Resize)
การปรับขนาดภาพเลือกใช้ได้ทั้งในไลบรารี่ของ opencv และ imutils ได้แก่ cv2.resize() และ imutils.resize() ฟังก์ชั่น resize ภายใน imutils เป็นวิธีการใหม่กว่าใน cv2.resize
import cv2
from utils import imutils
image = cv2.imread("raspberry-py-5.jpg"])
cv2.imshow("Original", image)
# Create a new image that is only 150 pixels wide manually
ratio = 150.0 / image.shape[1] # Calculate the ratio between the original width and the new width
dim = (150, int(image.shape[0] * ratio)) # Create new dimensions for the image
resized = cv2.resize(image, dim,
interpolation=cv2.INTER_AREA) # INTER_AREA: The algorithm used to calculate the interpolation
cv2.imshow("Resized (Width)", resized)
# Create a new image this is only 50 pixels high manually
ratio = 50.0 / image.shape[0] # Calculate the ratio between the original height and the new height
dim = (int(image.shape[0] * ratio), 50) # Create new dimensions for the image
resized = cv2.resize(image, dim,
interpolation=cv2.INTER_AREA) # INTER_AREA: The algorithm used to calculate the interpolation
cv2.imshow("Resized (Height)", resized)
# Use the utils function to resize the image based on a new height
resized = imutils.resize(image, height=200)
cv2.imshow("Resized with utils", resized)
ผลลัพธ์
การย้ายตำแหน่งภาพ (Transformation)
การย้ายตำแหน่งภาพ สามารถทำได้ด้วยฟังก์ชั่น cv2.warpAffine() และฟังก์ชั่น translate() ในไลบรารี่ imutils พารามิเตอร์ของฟังก์ชั่น imutils.translate() กำหนดระยะ x และ y ที่ต้องการย้ายภาพ ในตัวอย่างนี้ กำหนด translate(image, 0, 100) หมายถึงให้ภาพนี้ไม่ย้ายตำแหน่งในแกน x แต่ย้ายเฉพาะตำแหน่งในแกน y คือ ดันภาพลงมาด้านล่าง 100 พิกเซล
import cv2
from utils.imutils import translate
image = cv2.imread("raspberry-pi-6.jpg")
cv2.imshow("Original", image)
# Matrix done manually for demonstrations purposes
M = np.float32([[1, 0, -50], [0, 1, -90]]) # 50 pixels left and 90 pixels up
shifted = cv2.warpAffine(image, M, (image.shape[1], image.shape[0]))
cv2.imshow("Shifted Up and Left", shifted)
# Using the utils created
shifted = translate(image, 0, 100)
cv2.imshow("Shifted Down and Right", shifted)
ผลลัพธ์
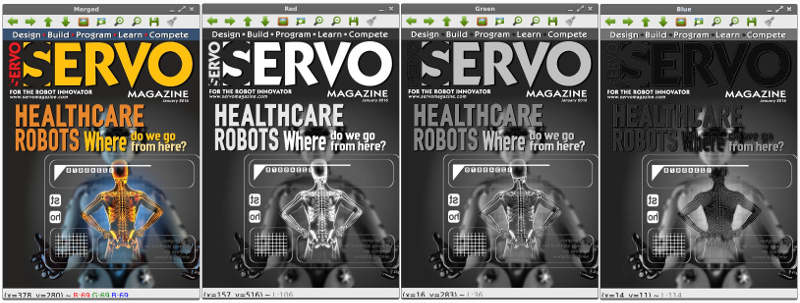
การแยกสีออกจากกันและการนำกลับมารวมกันใหม่อีกครั้ง
การแยกองค์ประกอบสีออกจากกันจะใช้คำสั่ง (blue, green, red) = cv2.split(image) หมายถึง องค์ประกอบแต่ละสีจะอยู่ในตัวแปร blue, gree, red ตามลำดับ
การแสดงองค์ประกอบสีแดง จะใช้คำสั่ง cv2.imshow("สีแดง", red) โดยคำว่าสีแดง จะเป็นแผ่นป้ายบนภาพที่แสดง และตัวแปร red คือ ตัวแปรที่ได้มาจากการสกัดแยกองค์ประกอบสีออกมา
การรวมสีเข้าด้วยกันใช้คำสั่ง cv2.merge เช่น merged = cv2.merge(blue, green, red]) เป็นต้น
# Simple splitting and merging functionality using the RGB colours of an image
# The image could also be split into HSV or L*a*b but RGB is the standard in OpenCV
import numpy as np
import cv2
image = cv2.imread("raspberry-pi-6.jpg")
(blue, green, red) = cv2.split(image) # Split the three channels of the image
# One way to visualize the different colours in the image
cv2.imshow("Red", red)
cv2.imshow("Green", green)
cv2.imshow("Blue", blue)
merged = cv2.merge([blue, green, red])
cv2.imshow("Merged", merged)
# Another way to visualize the colour channels
zeros = np.zeros(image.shape[:2], dtype="uint8")
cv2.imshow("Red", cv2.merge([zeros, zeros, red]))
cv2.imshow("Green", cv2.merge([zeros, green, zeros]))
cv2.imshow("Blue", cv2.merge([blue, zeros, zeros]))
ผลลัพธ์
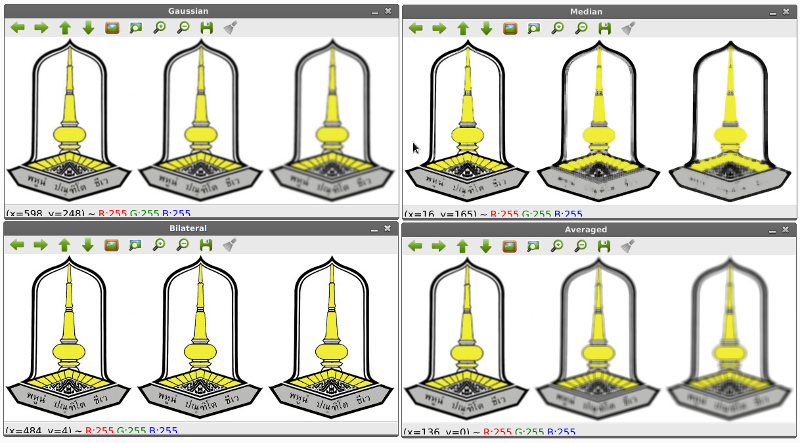
การทำภาพเบลอ (Blurring)
ในการทำภาพเบลอ จะมีฟังก์ชั่นหลายตัวให้เลือกใช้ได้แก่ 1) averaged function ใช้คำสั่ง cv2.blur() 2) Gaussian function ใช้คำสั่ง cv2.GaussianBlur 3) Median Blue ใช้คำสั่ง cv2.medianBlur และ4) Bilateral ใช้คำสั่ง cv2.bilateralFilter
import numpy as np
import cv2
image = cv2.imread("image-example.jpg")
cv2.imshow("Original", image)
# Blurring using the averaged function, where all the pixels in the neighborhood have equal weight
blurred = np.hstack([
cv2.blur(image, (3, 3)),
cv2.blur(image, (5, 5)),
cv2.blur(image, (7, 7))
])
cv2.imshow("Averaged", blurred)
# Blurring using the Gaussian function where pixels closer to the pixels color gets a higher weight
blurred = np.hstack([
cv2.GaussianBlur(image, (3, 3), 0),
cv2.GaussianBlur(image, (5, 5), 0),
cv2.GaussianBlur(image, (7, 7), 0)
])
cv2.imshow("Gaussian", blurred)
# Blurring using the median function where the kernel is replaced with the median pixel of the kernel neighborhood
# Median blur is usually the best function to remove noise from the image
blurred = np.hstack([
cv2.medianBlur(image, 3),
cv2.medianBlur(image, 5),
cv2.medianBlur(image, 7)
])
cv2.imshow("Median", blurred)
# Blurring using the bilateral function, that uses two Gaussian distributions to remove noise yet retain edges
# This method has great results yet are much slower than the other functions
blurred = np.hstack([
cv2.bilateralFilter(image, 5, 21, 21),
cv2.bilateralFilter(image, 7, 31, 31),
cv2.bilateralFilter(image, 9, 41, 41)
])
cv2.imshow("Bilateral", blurred)
ผลลัพธ์
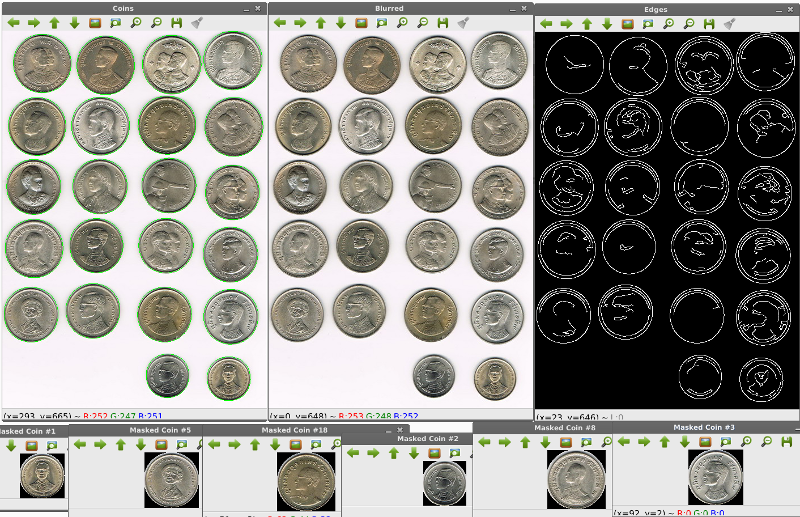
การหาตรวจจับเหรียญ ด้วยเทคนิคหาคอนทัวร์
เป็นเทคนิคที่นำมาใช้นับเหรียญเงิน และตัดบริเวณภาพเงินแต่ละเหรียญออกมา เก่งมาก นับเหรียญได้ถูกต้องว่ามี 22 เหรียญ และตัดขอบภาพด้วย !! ขั้นตอนคือ 1. โหลดภาพและแปลงให้เป็น grayscale 2. ทำให้เบลอ ด้วย cv2.GaussianBlue 3. หาขอบด้วย cv2.Canny 4. หาคอนทัวร์ของแต่ละเหรียญ ด้วย cv2.findContours(ภาพขอบ) 5. วาดเส้นคอนทัวร์รอบเหรียญเงิน 6. วนรอบ เท่ากับจำนวนเหรียญ และตัดภาพออกมาด้วยการใช้ mask
import numpy as np
import cv2
image = cv2.imread("image-example.jpg")
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (9, 9), 0) # For canny edge detection to work best, remember to blur the images
cv2.imshow("Blurred", image)
edged = cv2.Canny(blurred, 30, 150)
cv2.imshow("Edges", edged)
# RETR_EXTERNAL only takes the outermost contours
# CHAIN_APPROX_SIMPLE saves both computation and memory, by compressing all segments into their endpoint
(contours, _) = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # We only need the contours
print "I count %d coins in this image" % (len(contours)) # The contours are returned as a list
coins = image.copy()
# Draw a green circle around all contours with 1 pixel width
cv2.drawContours(coins, contours, -1, (0, 255, 0), 1) # the -1 parameter tells the function to draw all contours
cv2.imshow("Coins", coins)
# Crop all the coins from the image
for (i, c) in enumerate(contours):
(x, y, w, h) = cv2.boundingRect(c)
coin_name = "Coin #%d" % (i + 1)
coin = image[y:y + h, x:x + w]
mask = np.zeros(image.shape[:2], dtype="uint8")
((center_x, center_y), radius) = cv2.minEnclosingCircle(c)
cv2.circle(mask, (int(center_x), int(center_y)), int(radius), 255, -1)
mask = mask[y:y + h, x:x + w]
masked_coin_name = "Masked %s" % coin_name
cv2.imshow(masked_coin_name, cv2.bitwise_and(coin, coin, mask=mask))
ผลลัพธ์
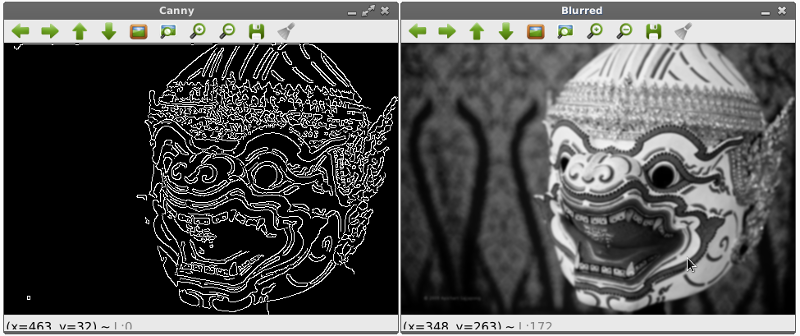
การหาเส้นขอบภายในภาพด้วยวิธี Canny
ขั้นตอนการหาขอบด้วยไลบรารี่ของ Canny Algorithm ใน OpenCV มีดังนี้ 1. อ่านภาพเข้ามาและแปลงเป็น GrayScale 2. ทำภาพเบลอด้วย cv2.GaussianBlur 3. หาขอบด้วย cv2.Canny(ภาพเบลอ)
import argparse
import cv2
image = cv2.imread("hanuman.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
image = cv2.GaussianBlur(image, (5, 5), 0) # For canny edge detection to work best, remember to blur the images
cv2.imshow("Blurred", image)
# Canny uses the sobel gradient detection to calculate the gradients in both axes.
canny = cv2.Canny(image, 30, 150) # The values given are two thresholds in the gradients (30 = non edges, 150 = edges)
cv2.imshow("Canny", canny)
ผลลัพธ์
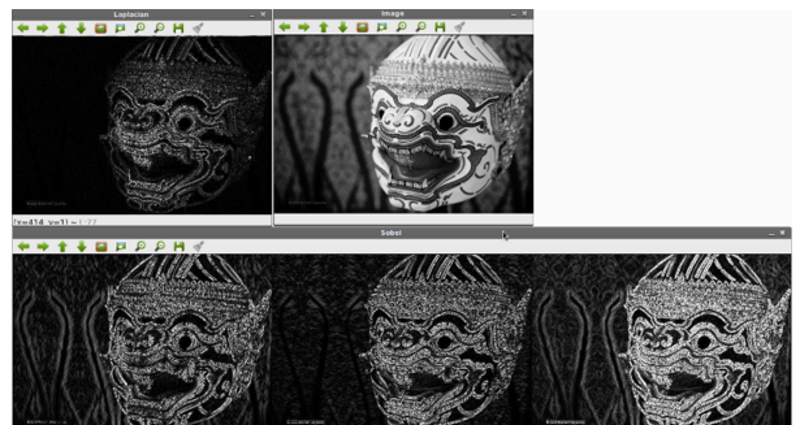
การหาเส้นขอบภายในภาพด้วยวิธี Sobel
ขั้นตอนการหาขอบด้วยไลบรารี่ของ Canny Algorithm ใน OpenCV มีดังนี้ 1. อ่านภาพเข้ามาและแปลงเป็น GrayScale 2. คำนวณหาความชันภายในภาพด้วย cv2.Laplacian 3. หาขอบด้วย cv2.Sobel(ภาพเบลอ) 4. ทำโอเปอร์เรเตอร์ or ด้วย cv2.bitwise_or
import numpy as np
import cv2
image = cv2.imread("hanuman.jpg"])
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv2.imshow("Image", image)
# To calculate the gradients of an image it is best not to use uint8 since you will miss some edges
# Calculate gradients using the laplacian method
lap = cv2.Laplacian(image,
cv2.CV_64F) # Convert the image to using 64 bit floats and calculate the gradients afterwards
lap = np.uint8(np.absolute(lap)) # Convert the image back into uint8
cv2.imshow("Laplacian", lap)
# Calculate the edges using the Sobel method
# In the Sobel method the gradients are calculated both horizontally and vertically
sobel_x = cv2.Sobel(image, cv2.CV_64F, 1, 0) # Remember to convert into 64 bit floats
sobel_y = cv2.Sobel(image, cv2.CV_64F, 0, 1)
sobel_x = np.uint8(np.absolute(sobel_x)) # remember to convert back into 8 bit unsigned integers
sobel_y = np.uint8(np.absolute(sobel_y))
sobel_combined = cv2.bitwise_or(sobel_x, sobel_y) # Combine the two gradients to get a better result
sobel = np.hstack([
sobel_x,
sobel_y,
sobel_combined
])
cv2.imshow("Sobel", sobel)
ผลลัพธ์
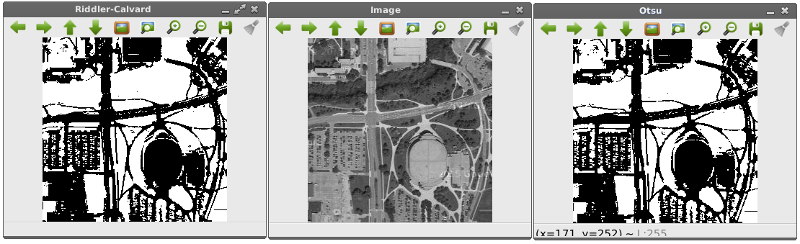
การหา Threshold ด้วยวิธี Otsu และ Riddler-calvard
ขั้นตอนการดำเนินการ 1. เปิดภาพเป็นเกรย์สเกล 2. ทำภาพเบลอ ด้วย cv2.GaussianBlur() 3. ต้องติดตั้ง mahotas ก่อน ด้วยคำสั่ง $ pip install mahotas 3.1 ทำให้พิกเซลที่มีค่าสูงกว่าค่า Threshold เป็นสีขาว 3.2 ทำให้พิกเซลทุกจุดเป็นสีดำถ้ามีต่ำกว่า Threshold 3.3 ทำอินเวอร์ท Threshold ด้วย cv2.bitwise_not() 4. หา Threshold ด้วยวิธี Riddler-calvard
import mahotas
import cv2
image = cv2.imread("map.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(image, (5, 5), 0)
cv2.imshow("Image", image)
# Finding the threshold using Otsu's method
T = mahotas.thresholding.otsu(blurred) # Calculate the threshold using Otsu's method
print "Otsu's threshold %d" % (T)
thresh = image.copy()
thresh[thresh > T] = 255 # Make all pixels above the threshold white
thresh[thresh <= T] = 0 # Make all pixels below the threshold black
thresh = cv2.bitwise_not(thresh) # A bitwise NOT inverts the on and off pixels in an image.
cv2.imshow("Otsu", thresh)
# Finding the threshold using the Riddler-calvard method
T = mahotas.thresholding.rc(blurred)
print "Riddler-Calvard: %d" % (T)
thresh = image.copy()
thresh[thresh > T] = 255
thresh[thresh <= T] = 0
thresh = cv2.bitwise_not(thresh) # A bitwise NOT inverts the on and off pixels in an image.
cv2.imshow("Riddler-Calvard", thresh)
ผลลัพธ์
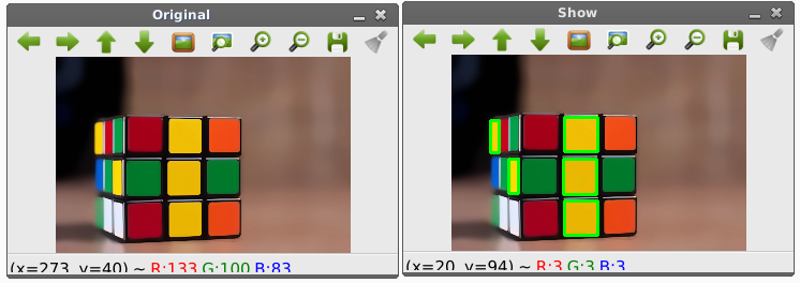
การหาพื้นที่สีเหลืองภายในภาพ
import numpy as np
import sys; sys.path.append('/usr/lib/pyshared/python2.7')
import cv2
from cv2 import *
im = cv2.imread('rubik.jpg')
im = cv2.bilateralFilter(im,9,75,75)
im = cv2.fastNlMeansDenoisingColored(im,None,10,10,7,21)
hsv_img = cv2.cvtColor(im, cv2.COLOR_BGR2HSV) # HSV image
COLOR_MIN = np.array([20, 100, 100],np.uint8) # HSV color code lower and upper bounds
COLOR_MAX = np.array([30, 255, 255],np.uint8) # color yellow
frame_threshed = cv2.inRange(hsv_img, COLOR_MIN, COLOR_MAX) # Thresholding image
imgray = frame_threshed
ret,thresh = cv2.threshold(frame_threshed,127,255,0)
contours, hierarchy = cv2.findContours(thresh,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
# print type(contours)
for cnt in contours:
x,y,w,h = cv2.boundingRect(cnt)
print x,y
cv2.rectangle(im,(x,y),(x+w,y+h),(0,255,0),2)
cv2.imshow("Show",im)
cv2.imwrite("extracted.jpg", im)
cv2.waitKey()
cv2.destroyAllWindows()
ผลลัพธ์
การสร้าง XML สำหรับคลังความรู้ในงานรู้จำด้วย OPenCV
ดาวน์โหลดเครื่องมือได้ที่นี่ -> Download 1.ข้อมูล 2 ส่วน 1) Positive ภาพที่มีวัตถุที่ต้องการหา (ควรมากกว่า 1000 ภาพ) 2) Negative ภาพที่ไม่มีวัตถุที่ต้องการหา (ควรมี 3000 ภาพ) 2. โหลดโปรแกรมช่วยสร้างภาพ Positive และ Negative ที่ http://www.mediafire.com/download/ame72vrp21uk1g4/tools.rar 3. สร้างภาพ Positive โดยเก็บรูปไว้ที่ tools/temp/positive/rawdata 3.1 เรียกไฟล์ objectmaker.exe จะให้เราลากเมาส์ครอบวัตถุ กด space bar = ยืนยัน, กด enter = ภาพถัดไป ทำไปจนเสร็จ จะได้ผลลัพธ์เป็นไฟล์ info.txt 4. สร้างภาพ Negative โดยเก็บรูปไว้ที่ tools/temp/negative 4.1 เรียกโปรแกรม create_list.bat จะทำการสร้างรายชื่อไฟล์ลงในเท็กซ์ไฟล์ 5. การสอน (Training) 5.1 สร้างเวคเตอร์ไฟล์ d:\tools\temp\createsamples.exe -info positive/info.txt -vec data/vector.vec -num 15 -w 20 -h 24
เมื่อ -info ไฟล์ info.tex จากการสร้าง positive images
- vec คือ ชื่อไฟล์ที่เก็บผลลัพธ์เวคเตอร์ที่สร้างนี้
- num คือ จำนวนภาพ positive sample
-w และ -h คือความกว้างและความสูง 6. นำไฟล์ vec มาสอน ด้วยคำสั่ง d:\tools\temp\haartraining.exe -data data/cascade -vec data/vector.vec -bg negative/infofile.txt -npos 15 -nneg 20 -nstages 15 -mem 1000 -mode ALL -w 20 -h 24 -nonsym
เมื่อ -data คือ ไฟล์ผลลัพธ์ , -vec คือเวคเตอร์ไฟล์ที่สร้างเอาไว้ในขั้น 5.1 , -bg คือไฟล์จาก negative sample
-npos คือจำนวนไฟล์ positive, -nneg คือจำนวนไฟล์ negative, -nstages คือจำนวน stage (ยิ่งมากยิ่งนาน) , -mem คือขนาดหน่วยความจำที่ใช้
-w -h คือ ความกว้างและความสูง
ปล. ขั้นตอนนี้ใช้เวลานานมาก !! 7. การสร้าง XML 7.1 คัดลอกไฟล์จาก tools/temp/data/cascade ไปไว้ที่ tools/cascade2xml/data 7.2 คัดลอกไฟล์ tools/temp/data/*.vec ไปไว้ที่ tools/cascade2xml 7.3 เรียก convert.bat จะได้ไฟล์ output.xml 8. เสร็จเรียบร้อย นำไฟล์ output.xml ไปใช้ในการตรวจจับวัตถุภายในภาพหรือวิดีโอได้แล้ว !!
การสร้าง XML สำหรับคลังความรู้ในงานรู้จำด้วย OPenCV เวอร์ชั่น (ผู้เขียนสรุปใจความสำคัญ)
https://youtu.be/yXm4heIHRr4 และ https://youtu.be/i_yjbMp30qM
โปรแกรมที่มาพร้อมกับ OpenCV สำหรับการ Train Cascade Classifier มีอยู่ 2 ตัว คือ opencv_haartraining และ opencv_traincascade โปรแกรม opencv_traincascade จะใหม่กว่าและเขียนด้วย C++ แต่โปรแกรมทั้งสองต่างกันที่ตัว opencv_traincascade สนับสนุนทั้งฟีเจอร์แบบ Haar และ LBP (Local Binary Patterns) - LBP features เป็นเลขจำนวนเต็ม ส่วน Haar features เป็นเลขทศนิยม - การใช้ LBP จะทำงานได้เร็วกว่า Haar features อย่างมาก - LBP และ Haar มีคุณภาพการตรวจจับขึ้นกับการ training โดยขึ้นกับข้อมูลดาต้าเซตที่นำมาสอนตลอดจนพารามิเตอร์ต่าง ๆ - การสอนด้วย LBP -based classifier จะให้คุณภาพพอกับของ Haar-based - opencv_traincascade สามารถบันทึก a trained cascade (xml) ในรูป objdetect module และในรูปแบบเดิมได้ - opencv_traincascade สามารถใช้ TBB สำหรับ multi-threading แต่ต้องคอมไพล์ opencv ด้วยตัวเลือกแบบ TBB - โปรแกรมช่วยอื่น ๆ ได้แก่ opencv_createsamples สำหรับสร้าง training dataset ของ positive images ผลลัพธ์เป็นไฟล์ .vec - โปรแกรม opencv_traincascade และ opencv_haartraining ใช้ข้อมูลจากไฟล์ .vec เป็น binary format - โปรแกรม opencv_performance ใช้ประเมินประสิทธิภาพและคุณภาพของ classifiers
Cascade Training !!
1. สร้างไดเร็คทอรี่เก็บงาน $ mkdir ~/haar
2. สร้างไเร็คทอรี่เก็บรูป $ mkdir ~/haar/img
2.1 สร้างไดเร็คทอรี่เก็บรูป positive ดังนี้ $ mkdir ~/haar/img/positive
2.2 สร้างไดเร็คทอรี่เก็บรูป negative ดังนี้ $ mkdir ~/haar/img/negative
2.3 คัดลอกรูปที่มีภาพวัตถุที่ต้องการตรวจจับลงในโฟลเดอร์ ~/haar/img/positive
2.4 คัดลอกรูปที่ไม่มีวัตถุที่ต้องการตรวจจับลงในโฟลเดอร์ ~/haar/img/negative
2.5 เขียนรายชื่อไฟล์ภาพของโฟลเดอร์ negative ลงใน ~/haar/img/negative ดังนี้ 1) cd ~/img/negative 2) ls *.bmp -1 > negative.txt
2.6 เขียนรายชื่อพาร์ทแบบเต็มของไฟล์ภาพ negative ดังนี้ 1) cd ~/haar/img/negative 2) find "$PWD" -name "*.bmp" > ../negativeNew.tex
3. ทำการเลือกขอบเขตวัตถุในภาพ positive เก็บลงในไฟล์ info.txt โดยเรียกโปรแกรม objectmarker.exe และเลือกขอบเขตของวัตถุในภาพ
จะได้ไฟล์ที่ชื่อว่า info.txt ออกมาเก็บไว้ในไดเร็คทอรี่เดียวกับ objectmarker.exe และข้อมูลภาพกำหนดไว้ว่าอยู่ในโฟลเดอร์ ~/haar/img/positive/rawdata (อยู่ใน rawdata)
ตัวอย่างผลลัพธ์ในไฟล์ info.txt คือ
rawdata/1.bmp 1 78 30 42 85
rawdata/2.bmp 1 54 31 61 70
rawdata/3.bmp 1 61 20 47 83
ปล.จะเห็นว่า รูปแบบคือ "ชื่อไฟล์ภาพ" -> 1 แทนมีวัตถุ -> พิกัด x,y -> ขนาดครอบวัตถุจากพิกัด x ไป ... พิกเซล -> ขนาดครอบวัตถุจากพิกัด y ไป ... พิกเซล
3.1 คัดลอกไฟล์ info.txt เป็น positive.txt และเปลี่ยนชื่อพาร์ทของไฟล์เป็นแบบเต็มพาร์ท
/home/learning/haar/img/rawdata/1.bmp 1 78 30 42 85
/home/learning/haar/img/rawdata/2.bmp 1 54 31 61 70
/home/learning/haar/img/rawdata/3.bmp 1 61 20 47 83
4. สร้างเวคเตอร์ไฟล์
$ cd ~/haar
$ opencv_createsamples -info positive.txt -v samples.vec -num (จำนวนภาพ) -h (ความสูงภาพ) -w (ความกว้างภาพ) PAUSE
ปล. ตอนนี้จะได้ไฟล์ samples.vec ออกมา เป็น bindary file
5. สอนด้วยคำสั่ง opencv_traincascade
$ cd ~/haar
$ opencv_traincascade -data (ชื่อไฟล์ .vec) -bg {ไฟล์ที่มีรายชื่อภาพ negative} -numPos {จำนวนภาพ positive} -numNeg {จำนวนภาพ negative} -w (ความกว้างของ ??) -h (ความสูง ??) -mode ALL
ผลลัพธ์
การสร้าง XML เวอร์ชั่นสมบูรณ์
https://www.youtube.com/watch?v=C0h0HEtKIPU
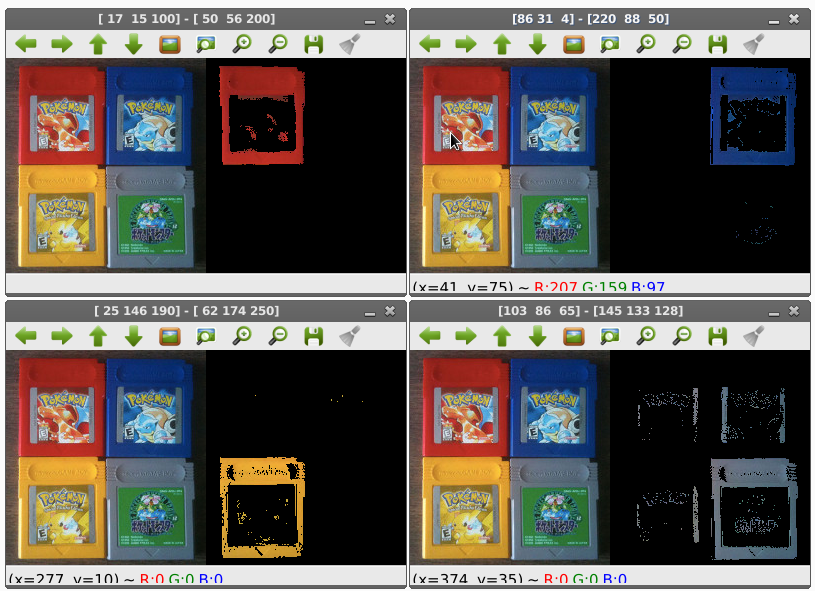
การแยกสีด้วย RGB Color Model
OpenCV เปิดไฟล์ภาพด้วยค่าปริยายคือ BGR หมายถึง สลับลำดับตำแหน่งสีจากเดิม RGB ดังนั้น การกำหนดค่าสีให้ระวังเรื่องนี้เป็นสำคัญ
import numpy as np
import argparse
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", help = "path to the image")
args = vars(ap.parse_args())
# load the image
image = cv2.imread(args["image"])
# define the list of boundaries
boundaries = [
([17, 15, 100], [50, 56, 200]),
([86, 31, 4], [220, 88, 50]),
([25, 146, 190], [62, 174, 250]),
([103, 86, 65], [145, 133, 128])
]
for (lower, upper) in boundaries:
lower = np.array(lower, dtype = "uint8")
upper = np.array(upper, dtype = "uint8")
print lower, upper
# find the colors within the specified boundaries and apply the mask
mask = cv2.inRange(image, lower, upper)
output = cv2.bitwise_and(image, image, mask = mask)
cv2.imshow("images", np.hstack([image, output]))
ผลลัพธ์
ทฤษฎี Harr-Like Features สำหรับงานรู้จำใบหน้า -> ดาวน์โหลดเอกสาร
1. ในปี ค.ศ. 2001 Viola-Jones เสนอการจำลองรูปแบบด้วย Haar-Like มี 3 ขั้นตอน 1) การอินทริเกรตรูป (Integral Image) 2) การค้นหา Haar-Like ด้วย Adaboost 3) การรวบรวมตัวใช้จำแนกกลุ่มแบบเรียงต่อกันไป (Cascade Classification) พบว่า วิธีการของ Haar-Like มีความแม่นยำมากที่สุด สามารถดึงลักษณะเด่นของใบหน้าออกมาได้ 2. ปัจจุบัน (พ.ศ.2554) งานตรวจจับใบหน้าแบ่งเป็น 4 ด้าน 1) วิธีฐานความรู้ (Knowledge based) โดย pitas ค.ศ. 1997 ใช้ลักษณะดวงตา 2 ดวงตำแหน่งสมมาตรกับแนวระนาบ มีจมูกและปากที่สำพันธ์กับระยะทาง 2) วิธีค้นหาลักษณะเด่น (Feature invariant approaches) พบว่าในปี ค.ศ. 1998 Yow และ Cipolla ทำการสกัดลักษณะเด่นของคิ้ว ตา จมูก ปาก และเส้นผมด้วย Edge Detection จากนั้นใช้สถิติอธิบายความสัมพันธ์ วิธีนี้มีข้อเสียคือ สภาพแสงเงามีผลต่อการตรวจจับขอบวัตถุ 3) วิธี Template Matching methods ใช้ใบหน้าตรง เช่น ในปี ค.ศ. 1998 Scassellati กำหนดแบบใบหน้า 16 พื้นที่ 23 ความสัมพันธ์ นำมาผ่านการคำนวณสหสัมพันธ์ (Correlation Values) กับหน้ามาตรฐานที่มีตำแหน่งดวงตา จมูก ปากที่เป็นอิสระกัน โดยใช้ค่าสหสัมพันธ์เป็นสำคัญ วิธีนี้ทำได้ง่ายแต่ตรวจจับใบหน้าไม่ดีนักเพราะตำแหน่ง และรูปทรงใบหน้าที่ต่างจากมาตรฐาน 4) วิธี Appearance-based method ใช้การเรียนรู้ใบหน้าจากภาพที่มีหน้าและไม่มีหน้าคน โดยศึกษาความสัมพันธ์ระหว่างรูปที่มีใบหน้าและไม่มีใบหน้า ผ่านวิธีการสถิติและการเรียนรู้ของเครื่องจักร และจัดเป็น ก) การกระจาย (Distribution Modes) ข) การจำแนก (Discriminant Funtions) และ ค) การลดมิติ (Dimension Reduction) ในปี ค.ศ. 1998 Sung และ Pogio ใช้การประมาณความหนาแน่นของแบบหน้าและไม่มีแบบหน้าด้วยการใช้เกาส์เซียน (Gaussian) สรุปได้ว่า งานวิจัยด้วยวิธี Appearance-based ให้ประสิทธิภาพดีกว่าวิธีอื่น ๆ โดยเฉพาะงานของ Viola และ Jones นำเสนอในปี ค.ศ. 2001 จับใบหน้าได้รวดเร็วมาก 3. วิธีการของ Paul viola Michael J. Jones นำเสนอในปี ค.ศ. 2001 แบ่งเป็น 3 ขั้นตอน ก) การอินทริเกรตภาพ ข) การค้นหารูปแบบด้วย Adaboost และ ค) การจัดเรียงตัวจำแนก (Cascaded Classifier) เริ่มจากการนำภาพมาแบ่งเป็นภาพย่อย ๆ (sub-window) จากนั้นนำภาพย่อย ๆ มาตรวจหาใบหน้า สมัยก่อนใช้การปรับขนาดภาพหลายขนาด โดยใช้ตัวตรวจจับที่ค้นหาวัตถุแบบคงที่ซึ่งไม่ค่อยมีประสิทธิภาพเพราะใช้เวลานาน ดังนั้น Viola และ Jones แนะนำว่าวใช้วิธี Haar-like แทนตัวตรวจจับโดยจะปรับตัวตรวจจับแทนที่จะปรับขนาดภาพ และตรวจจับใบหน้าหลาย ๆ รอบแต่ละรอบใช้ตัวตรวจจับต่างกัน พบว่าเวลาการคำนวณไม่แตกต่างกันแต่เวลาการตรวจจับใบหน้าแต่ละรอบมีค่าคงที่ไม่ค่อยเปลี่ยนแปลงแม้ว่าขนาดตัวตรวจจับจะแตกต่างกันก็ตาม ขั้นตอนการอินทริเกรตภาพ ใช้หลักการนำสี่เหลี่ยมมาแบ่งเป็นส่วนแรเงาและไม่แรเงา ใช้การหาผลต่างระหว่างความเข้มในส่วนแรเงากับส่วนไม่แรเงา และนำไปเทียบกับค่าเทรสโช (Threshold) กับขั้ว (Polarity) ที่จะตัดสินใจว่าภาพที่จะนำมาใช้เป็นบวก (มีใบหน้า) หรือเป็นลบ (ไม่มีใบหน้า) โดยวิธีของ Haar มี 3 แบบ คือ ก) สี่เหลี่ยม 2 อัน ข) สี่เหลี่ยม 3 อัน และ ค) สี่เหลี่ยม 4 อันการหาผลรวมเขียนแทนด้วย $i_{s}(x_{1}, x_{2}, y_{1}, y_{2}) = \sum_{x=x_{1}}^{x_{2}}\sum_{y=y_{1}}^{y_{2}} i(x,y)$ ขั้นตอนการเรียนรู้ด้วยวิธี Adaboost ได้แก่ 1) เลือกภาพจำนวน N ภาพ มีคำตอบด้วยว่าเป็นภาพมีใบหน้าคนหรือไม่มีใบหน้าคน 2) กำหนดค่าน้ำหนัก 3) หานอร์มัลไลซ์ , ความผิดพลาดต่ำสุด, ปรับน้ำหนัก ขั้นรวมตัวจำแนกบบเรียงต่อกันไป (Cascaded Classifier)
การวิจัยต่อเนื่อง 1) ปี ค.ศ.2002 Lienhart และ Maydt ได้นำ haar-like มาหมุน 45 องศา พบว่าเพิ่มความถูกต้อง 10% 2) ปี คศ. 2003 Viola และ Jones ตรวจจับใบหน้าที่มุมเอียงไม่ตั้งตรงและด้านข้างได้ 3) ปี ค.ศ. 2005 Mita และ Kaneko ได้นำ Haar-like รวมกับ Join Haar-like Feature ให้ทนสัญญาณรบกวนของแสง 4) ปี ค.ศ. 2006 Wilson และ Fernandez ประยุกต์ Haar Classifier ตรวจจับ ตา คิ้ว จมูก ปาก 5) ปี ค.ศ. 2007 Chen และ Liu ปรับปรุงกับภาพสีแทนแบบเดิมที่ตรวจเฉพาะภาพเกรย์สเกล 6) ปี ค.ศ. 2009 Khac นำเสนอวิธีใหม่ เรียก Variance Based Haar Like โดยคำนวณค่าความแปรปรวนและค่าเฉลี่ยของพื้นที่สี่เหลี่ยมจากวิธีอินทริเกรตภาพ มาเป็นการใช้ support vector machine แทนการเรียนรู้ด้วย Adaboost พบว่าการตรวจจับใบหน้าใช้เวลาดลดลงและมีความถูกต้องเพิ่มขึ้น 4.21% 7) ปี. ค.ศ. 2010 Lu นำเสนอ Separate Haar Feature คือเพิ่มช่องว่างให้กับพื้นที่สี่เหลี่ยม8) ในปี ค.ศ. 2011 Pavani เสนอการกำหนดค่าน้ำหนักอย่างเหมาะสม โดยผลรวมทุกแบบต้องมีค่ารวมเท่ากับ 0 ทำให้ใช้เวลาน้อยลงและเพิ่มความถูกต้องอีก แต่แม้ว่าจะอ้างว่าแม่นยำแต่ยังเทียบเชิงตัวเลขยังทำไม่ได้ เพราะใช้ฐานข้อมูลใบหน้าที่แตกต่างกัน
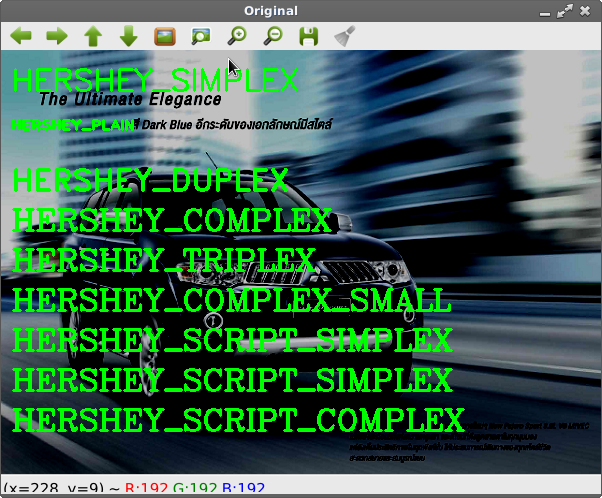
การเขียนข้อความลงบนภาพด้วย cv2.putText()
import numpy as np
import cv2
fonts = [cv2.FONT_HERSHEY_SIMPLEX,
cv2.FONT_HERSHEY_PLAIN,
cv2.FONT_HERSHEY_DUPLEX,
cv2.FONT_HERSHEY_COMPLEX,
cv2.FONT_HERSHEY_TRIPLEX,
cv2.FONT_HERSHEY_COMPLEX_SMALL,
cv2.FONT_HERSHEY_SCRIPT_SIMPLEX,
cv2.FONT_HERSHEY_SCRIPT_COMPLEX]
image = cv2.imread("car.png")
cv2.putText(image,'HERSHEY_SIMPLEX',(10,40), fonts[0], 1,(0,255,0),2)
cv2.putText(image,'HERSHEY_PLAIN',(10,80), fonts[1], 1,(0,255,0),2)
cv2.putText(image,'HERSHEY_DUPLEX',(10,140), fonts[2], 1,(0,255,0),2)
cv2.putText(image,'HERSHEY_COMPLEX',(10,180), fonts[3], 1,(0,255,0),2)
cv2.putText(image,'HERSHEY_TRIPLEX',(10,220), fonts[3], 1,(0,255,0),2)
cv2.putText(image,'HERSHEY_COMPLEX_SMALL',(10,260), fonts[3], 1,(0,255,0),2)
cv2.putText(image,'HERSHEY_SCRIPT_SIMPLEX',(10,300), fonts[3], 1,(0,255,0),2)
cv2.putText(image,'HERSHEY_SCRIPT_SIMPLEX',(10,340), fonts[3], 1,(0,255,0),2)
cv2.putText(image,'HERSHEY_SCRIPT_COMPLEX',(10,380), fonts[3], 1,(0,255,0),2)
cv2.imshow("Original", image)
ผลลัพธ์
แก้ปัญหาการคอมไพล์ OpenCV !!
คู่มือการคอมไพล์ OpenCV ปล. https://linuxconfig.org/introduction-to-computer-vision-wit… ไฟล์โค๊ด ชื่อ image-conversion.c มีเนื้อโค๊ดคือ
#include "highgui.h"
int main( int argc, char** argv ) {
IplImage* img = cvLoadImage( argv[1]);
cvSaveImage( argv[2] , img);
cvReleaseImage( &img );
return 0;
}
คอมไพล์ด้วยคำสั่งตามที่คู่มือบอก ดังนี้ $ g++ `pkg-config opencv --cflags --libs` image-conversion.c -o image-conversion >>>> ผลลัพธ์คอมไพล์ไม่ผ่าน ทำไม ??? ทดลองเปลี่ยน เอาไฟล์ขึ้นก่อน ตามด้วยพารามิเตอร์ ดังนี้ $ g++ image-conversion.c -o image-conversion `pkg-config opencv --cflags --libs` >>>> ผลลัพธ์คอมไพล์ผ่าน ทำไม ? ทดลองอีกครั้ง !! ทดลองเปลี่ยนเครื่องหมาย single quote (เอียง) เป็น (ตรง ๆ) ดันคอมไพล์ไม่ผ่าน เป็นอะไรมากมั้ยคอมไพล์เลอร์ ??? $ g++ image-conversion.c -o image-conversion 'pkg-config opencv --cflags --libs'