 ตัวแปร dummy
ตัวแปร dummy
เขียนโดย ดร.จักรกฤษณ์ แสงแก้ว วันที่ 24 กรกฎาคม 2562
บทนำ
ข้อมูลแบ่งเป็น 2 ประเภท คือ 1) ข้อมูลเชิงปริมาณ (Quantitative variable) ซึ่งได้จากเครื่องมือวัด เช่น น้ำหนัก ความสูง เป็นต้น 2) ข้อมูลเชิงคุณภาพ (Qualitative variable) ซึ่งไม่สามารถวัดค่าเป็นตัวเลข เช่น อาชีพ เพศ เป็นต้น ในหัวข้อนี้จะทำการศึกษาตัวแปร Dummy หรือ Categorical variable ซึ่งเป็นการแปลงข้อมูลเชิงคุณภาพให้สามารถนำไปใช้แทนข้อมูลเชิงปริมาณ ไลบรารี่สำหรับจัดการตัวแปร Dummy ที่จะศึกษาในหัวข้อนี้คือ Pandas โดยใช้คำสั่ง get_dummies() ขอให้พิจารณาตัวอย่างต่อไปนี้
การสร้างตัวแปร Dummy
การประกาศใช้งานไลบรารี่ pandas และตั้งชื่อย่อว่า pd ด้วยคำสั่ง import pandas as pd จากนั้นอ่านข้อมูลดาต้าเซ็ตด้วยคำสั่ง pd.read_csv() และแสดงผลตัวแปร df (data frame) ดังนี้
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/dsdi/dataset/master/th-carprices.csv")
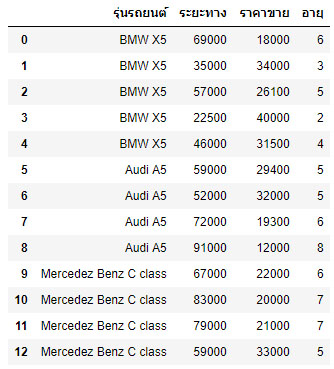
df
ผลลัพธ์ :
อธิบาย :
ไฟล์ th-carprices.csv ประกอบด้วยตัวแปรทั้งหมด 4 ชุด ได้แก่ รุ่นรถยนต์ ระยะทาง ราคาขาย และอายุการใช้งาน จะพบว่าตัวแปร รุ่นรถยนต์มีข้อมูลเป็นเชิงคุณภาพ ดังนั้น ในการนำไปใช้สร้างสมการรีเกรสชั่น จำเป็นต้องแปลงให้อยู่ในเชิงปริมาณโดยใช้ตัวแปร Dummy
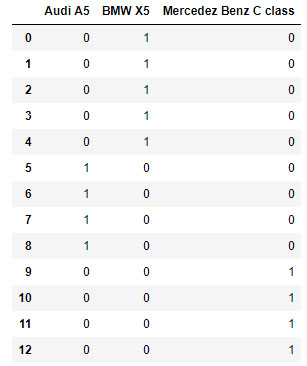
dummies = pd.get_dummies(df['รุ่นรถยนต์']) dummies
อธิบาย :
ภายในตัวแปร "รุ่นรถยนต์" ประกอบด้วยยี่ห้อรถยนต์ ได้แก่ 1) รุ่น BMW X5 2) รุ่น Audi A5 และ 3) รุ่น Mercedez Benz จากตัวอย่างด้านบนทำการสร้างตัวแปรชื่อ dummies ขึ้นมาใหม่ นำข้อมูลจากคอลัมน์ "รุ่นรถยนต์" มาสร้างเป็นตัวแปร dummy ด้วยคำสั่ง get_dummies() ผลลัพธ์แสดงค่าตัวแปร dummies ได้ ดังนี้
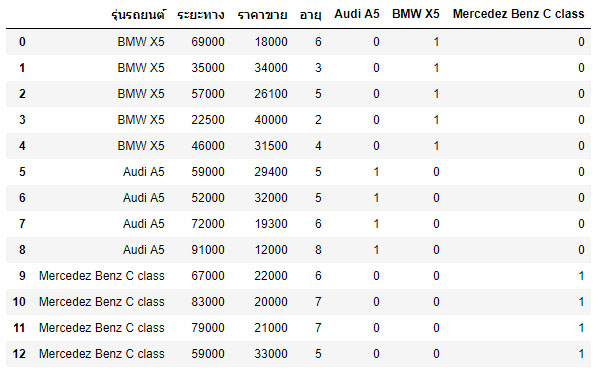
df = pd.concat([df,dummies],axis='columns') df
อธิบาย :
ตัวแปร dummies ที่สร้างเสร็จแล้วสามารถนำมาต่อท้ายคอลัมน์และเก็บเอาไว้ในตัวแปร df ด้วยคำสั่ง concat() โดยนำข้อมูลจากตัวแปร df เดิม รวมกับกับ dummies และเขียนทับกลับไปยังตัวแปร df เหมือนเดิม ดังนั้น ตอนนี้ตัวแปร df จะมีข้อมูลจากเดิม 4 คอลัมน์และเพิ่มอีก 3 คอลัมน์ รวมเป็น 7 คอลัมน์ ดังนี้
y = df['ราคาขาย'] y
อธิบาย :
โมเดลรีเกรสชั่นที่กำลังศึกษาอยู่นี้จะใช้ตัวแปร ราคาขาย เป็นตัวแปรตาม (independent variable) และเก็บในตัวแปรชื่อ y เขียนเป็นคำสั่งไพธอน คือ y=df['ราคาขาย'] ผลลัพธ์ แสดงได้ดังนี้
0 18000
1 34000
2 26100
3 40000
4 31500
5 29400
6 32000
7 19300
8 12000
9 22000
10 20000
11 21000
12 33000
Name: ราคาขาย, dtype: int64
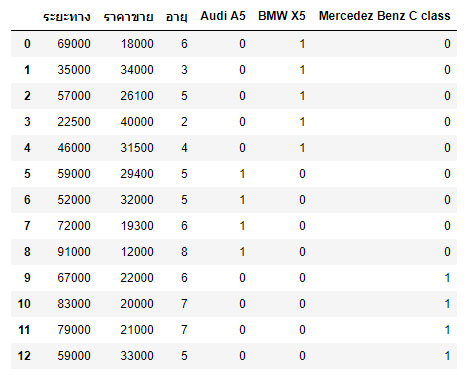
X = df.drop(["รุ่นรถยนต์","ราคาขาย"],axis='columns') X
อธิบาย :
ตัวแปร X ถูกสร้างขึ้นมาเพื่อเก็บตัวแปรอิสระ (independent variable) ที่มีตัวแปร dummies รวมอยู่ด้วย โดยจะตัดเอาตัวแปรตามทิ้งไป นั่นคือลบแอตทริบิวส์ รุ่นรถยนต์และราคาขาย ทิ้งไปด้วยคำสั่ง X = df.drop(["รุ่นรถยนต์","ราคาขาย"],axis='columns') โดยกำหนดอาร์กิวเมนต์ axis เป็นแนวตั้ง หรือคอลัมน์ ผลลัพธ์ตัวแปร X แสดงได้ดังนี้
from sklearn.linear_model import LinearRegression model = LinearRegression()
อธิบาย :
ในขั้นต่อไปเป็นการสร้างสมการ Multiple Linear Regression ด้วยไลบรารี่ Scikit-Learn โดยบรรทัดที่ 12 ประกาศขอใช้คลาส LinearRegression จากไลบรารี่ Scikit-Learn
บรรทัดที่ 13 : เป็นการสร้างตัวแปร model เป็นอ็อบเจ็คของคลาส LinearRegression() เพื่อใช้สำหรับสร้างสมการลีเนียร์ในขั้นต่อไป
model.fit(X,y)
อธิบาย : บรรทัดที่ 14 : คำสั่ง fit() เป็นการสร้างสมการทางคณิตศาสตร์ในตัวอย่างนี้ใช้ Multiple Linear Regression โดยป้อนตัวแปรอิสระ (X) และตัวแปรตาม (y) ลงในฟังก์ชั่น fit()
model.score(X,y)
อธิบาย : บรรทัดที่ 15 : คำสั่ง Score() ใช้สำหรับแสดงค่าสถิติ R-Squared ของสมการ โดยป้อนตัวแปรอิสระ (X) และตัวแปรตาม (y) ลงในฟังก์ชั่น score() ผลลัพธ์ที่ได้มีค่า 0.9417
model.coef_
อธิบาย : บรรทัดที่ 16 : ตัวแปร model.coef_ แสดงค่าสหสัมพันธ์ของ ระยะทาง , อายุ , รุ่น Audi A5 , รุ่น BMW X5 และ รุ่น Mercedez Benz มีค่าเท่ากับ [-3.70122094e-01, -1.33245363e+03, 6.10375284e+02, -3.67429130e+03, 3.06391602e+03]) ตามลำดับ
ซอร์สโค๊ดการทำงานทั้งหมด
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/dsdi/dataset/master/th-carprices.csv")
df
dummies = pd.get_dummies(df['รุ่นรถยนต์'])
dummies
df = pd.concat([df,dummies],axis='columns')
df
y = df['ราคาขาย']
y
X = df.drop(["รุ่นรถยนต์","ราคาขาย"],axis='columns')
X
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X,y)
model.score(X,y)
model.coef_